rabbitmq
rabbitmq是一种分布式消息中间件, 常用与上下游的“逻辑解耦+物理解耦”(异步)。
异步调用的优势
- 耦合度低,拓展性强
- 异步调用,无需等待,性能好
- 故障隔离,下游服务故障不影响上游业务
- 缓存消息,流量削谷填峰
异步调用的问题
- 不能立即得到调用结果,时效性差
- 不确定下游业务执行是否成功
- 业务安全依赖于Broker的可靠性
启动命令
docker run -d --name rabbitmq -p 5672:5672 -p 15672:15672 -e RABBITMQ_DEFAULT_USER=user -e RABBITMQ_DEFAULT_PASS=password rabbitmq:latest提示
rabbitmq的后台管理页面默认是关闭的,需要手动开启插件:rabbitmq-plugins enable rabbitmq_management
消息发送模型
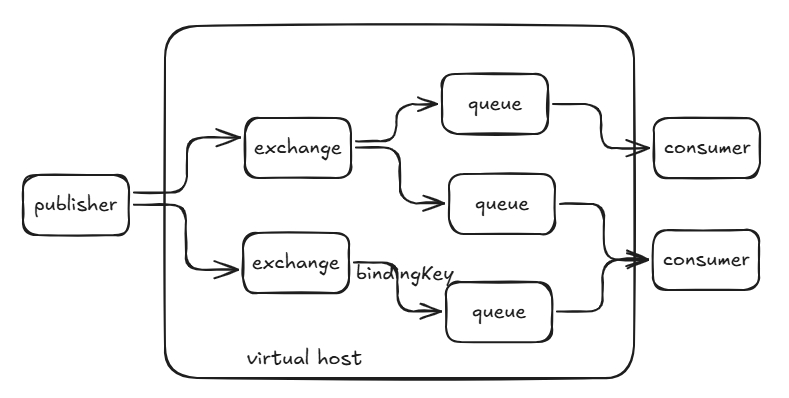
- 消息发送者
- 交换机
- 队列
- 消息消费者
- 路由键
- 虚拟主机
消费模型
- work模型
- 多个消费者绑定到一个队列,可以加块消息处理速度。
- 同一个消息只会被一个消费者处理。
- 通过设置prefetch来控制消费者预取消息的数量,处理完一条再处理下一条(可以一定程度上解决消息堆积问题)。
交换机
Fanout(广播)
- 将消息广播到每一个跟其绑定的queue
Direct(定向)
- 会将接收到的消息按照RoutingKey投递到指定的队列
- 每个Queue都应该与Exchange绑定一个BindingKey
Topic(主题)
- RoutingKey是多个单词列表以.分割
- Queue与Exchange指定BindingKey时可以使用通配符
- #: 0个或者多个单词
- *: 一个单词
消息可靠性问题
在正常的业务流程中可能会存在一系列问题
- publisher和mq之间交互出现故障
- mq宕机导致消息没有投递出去
- consumer收到消息处理的时候异常
发送者的可靠性
- 生产者重连 由于网络波动可能出现客户端连接mq失败的情况,可以通过配置开启连接失败后的重连机制
spring:
application:
name: publisher
rabbitmq:
host: 127.0.0.1
port: 5672
username: user
password: password
virtual-host: /warmwind
listener:
simple:
prefetch: 1 # 每次只处理一个消息
connection-timeout: 1s #超时时间
template:
retry:
enabled: true #开启重试
initial-interval: 1s # 失败后的初始等待时间
multiplier: 1 # 失败后下次等待时长倍数, 下次等待时长 = initial-interval * multiplier
max-attempts: 3 # 最大重试次数提示
当网络不稳定的时候,可以利用重试机制提高消息发送的成功率,不过springamqp的重试是阻塞式的会影响业务性能, 如果对业务性能有要求,建议禁用重试机制,如果一定要使用,需要配置合理的等待时长和重试次数,也可以考虑用异步线程来执行发送消息的业务
- 生产者确认
rabbitmq提供了publisher confirm和publisher return两种确认机制,开启确认机制后,在mq成功收到消息后会返回确认消息给生产者
- 消息投递到了mq,但是路由失败,此时会通过publisher return返回路由异常原因,然后返回ack,告知投递成功(出现这种情况要么是交换机没有正常绑定队列,要么是代码写的有问题,可以在开发层面避免,一般不会出现)
- 临时消息投递到了mq,并且入队成功,返回ack,告知投递成功
- 持久化消息投递到了mq,并且入队完成持久化成功,返回ack,告知投递成功
- 其他情况都会返回nack,告知投递失败
spring:
rabbitmq:
publisher-confirm-type: correlated # 开启publisher confirm机制(none: 关闭,simple:同步阻塞等待mq回执,correlated:mq异步回调)
publisher-returns: true # 开启publisher returns机制(一般情况不用开启)publisher return(每个RabbitTemplate只能配置一个ReturnsCallback):
@Configuration
public class CommonConfig implements ApplicationContextAware {
@Override
public void setApplicationContext(ApplicationContext applicationContext) throws BeansException {
RabbitTemplate rabbitTemplate = applicationContext.getBean(RabbitTemplate.class);
rabbitTemplate.setReturnsCallback(returnedMessage -> System.out.println("消息被退回:" + returnedMessage));
}
}publisher confirm(发送消息,指定消息id,消息ConfirmCallback):
@Test
void contextLoads() {
String uuid = IdUtil.fastSimpleUUID();
CorrelationData cd = new CorrelationData(uuid);
rabbitTemplate.setConfirmCallback((correlationData, ack, cause) -> {
if (ack) {
System.out.println("send msg success,id: " + correlationData.getId());
} else {
System.out.println("send msg err,id: " + cd.getId() + ", reason: " + cause);
}
});
rabbitTemplate.convertAndSend("ww.direct.exchange", "notice", "test notice", cd);;
}提示
生产者确认机制需要额外的网络和系统资源开销,一般不使用
如果一定要使用无需开启publisher return机制,路由失败一般是业务问题
对于nack消息可以使用有限重试,依然失败则记录异常消息
mq的可靠性
在默认情况下,mq将收到的消息放到内存里,降低消息的延迟,但是会导致一些问题:
- mq挂掉后消息丢失
- 内存空间有限,当消费者故障或者处理太慢的情况下会造成消息积压,引发mq阻塞
解决方案:
数据持久化
- 交换机持久化
- 队列持久化
- 消息持久化(springboot发送消息默认是持久化的)
Lazy Queue(rabbitmq3.6.0后引入,3.12.0后默认启用无法更改)
- 接收到消息直接写入磁盘而非内存,内存中只保留最近的消息默认2048条
- 消费者需要消费时才会从磁盘从取出并加载
- 支持百万消息的存储
消费者的可靠性
为了确认消费者是否成功处理消息,rabbitmq提供了消费者确认机制,当消费者处理消息后,应该向mq 发送一个回执,告知mq消息处理完毕,回执有三种状态:
- ack:成功处理消息,rabbitmq中队列中删除消息
- nack:消息处理失败,rabbitmq需要再次投递消息
- reject:消息处理失败并拒绝消息,rabbitmq从队列中删除消息
sringamqp以已经默认实现了,通过配置文件选择ack处理方式:
- none:不处理,消息投递后消费者立马返回ack,消息立刻从mq删除,非常不安全,不建议使用
- manual:手动模式,需要在业务代码中调用api,发送ack或者reject,存在业务入侵,但是更灵活
- auto:自动模式,springamqp,利用aop对消息处理逻辑做了增强,当业务执行正常的时候返回ack,当业务出现异常时,根据异常返回不同结果
- 业务异常:返回nack
- 消息处理或者校验异常:返回reject
spring:
rabbitmq:
listener:
simple:
acknowledge-mode: auto # 自动确认失败重试机制:当消费者消费失败并且返回nack时,消息会不断重新入队,然后再次异常,无限循环,导致mq的消息处理彪升,带来不必要的压力, 可以利用spring的本地消费重试机制,而不是无限mq队列
spring:
rabbitmq:
template:
retry:
enabled: true #开启重试
initial-interval: 1s # 失败后的初始等待时间
multiplier: 1 # 失败后下次等待时长倍数, 下次等待时长 = initial-interval * multiplier
max-attempts: 3 # 最大重试次数
stateless: true # 如果业务有事务这里为false在开启消费重试之后,重试次数耗尽,如果消息依然失败,则由MessageRecoverer接口处理,包含三种实现
- RejectAndDontRequeueRecoverer:重试耗尽,直接reject,丢弃消息,默认
- ImmediateRequeueMessageRecoverer:重试耗尽,返回nack,重新入队
- RepublishMessageRecoverer:重试耗尽,失败消息投递到指定的交换机
业务幂等性
同一个业务,执行一次或者执行多次对业务状态的影响是一致的
唯一消息id
- 给每条消息都生产一个唯一的业务标识,与消息一起投递给消费者
- 消费者收到消息后,处理自己的业务,业务处理成功后将处理成功的消息id保存到数据库
- 如果下次又收到相同的消息,去数据库判断是否存在,存在则为重复消息直接放弃
// 通过MessageConverter实现,如果后续需要改为如雪花id,则可以直接配置后置处理器
@Bean
public MessageConverter messageConverter() {
Jackson2JsonMessageConverter jackson2JsonMessageConverter = new Jackson2JsonMessageConverter();
jackson2JsonMessageConverter.setCreateMessageIds(true);
return jackson2JsonMessageConverter;
}基于业务本身判断是否有幂等性
延迟消息
- 生产者发送消息时,指定一个时间,在一段时间后才会收到消息
- 在一段时间后才执行的任务
死信交换机
当一个队列中的任意一条消息满足下列情况之一就会成为死信:
- 消费者使用basic.reject或basic.nack声明消费失败,并且消息的request参数设为false
- 消息是一个过期消息,达到了队列或消息设置的时间,超时无人消费
- 要投递的队列满了,最早的消息可能成为死信
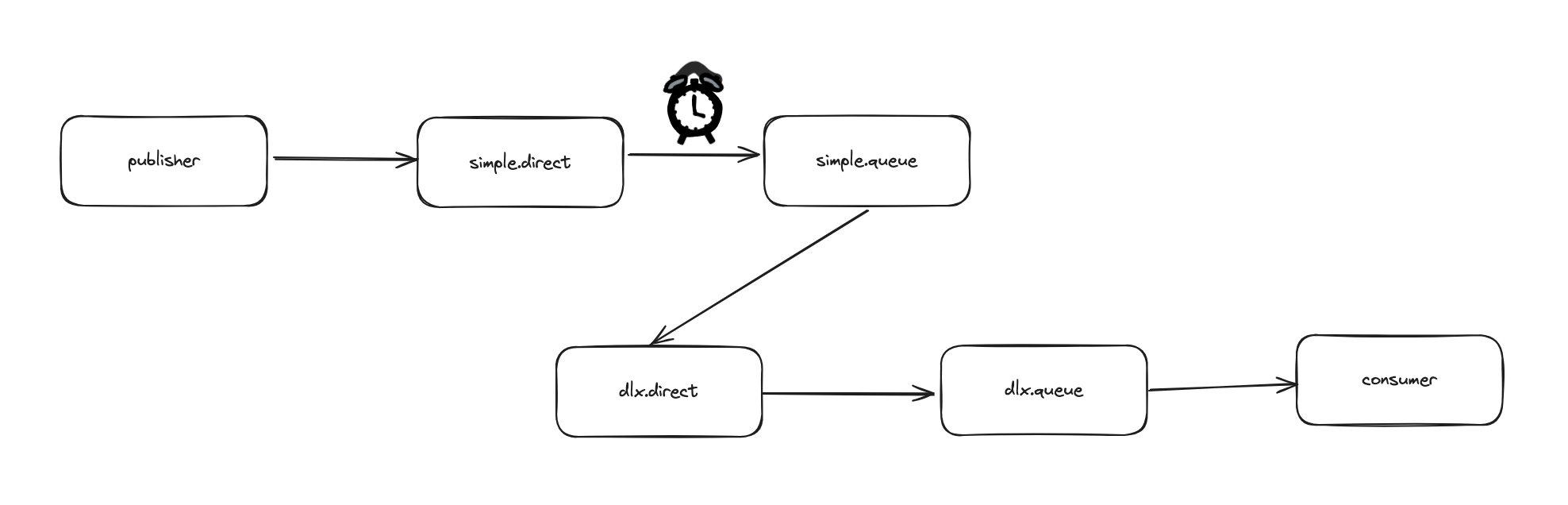
如果队列通过dead-letter-exchange属性指定了一个交换机,那么该队列中的死信就会投递到该交换机中。可以用来实现延时任务
- 消费者投递一条延时消息
- 当消息在队列里过期后被投递到死信交换机
- 死信交换机投递到死信队列
- 消费者消费
延迟消息插件
rabbitmq官方提供的插件,原生支持延迟消息,原理是设计了一种支持延迟消息的交换机,当消息投递到交换机可以暂存一段时间, 到期后再投递到队列
// consumer
@RabbitListener(bindings = @QueueBinding(
value = @Queue(name = "delay.queue"), declare = "true",
exchange = @Exchange(name = "delay.direct", type = ExchangeTypes.DIRECT, delayed = "true"),
key = {"delay"}
))
public void listenDlxQueue(String message) {
System.err.println("延迟消息:" + message);
}
// publisher
@Test
void sendTTLMessage() {
rabbitTemplate.convertAndSend("delay.direct", "delay", "delay message", message -> {
message.getMessageProperties().setDelayLong(10000L);
return message;
});
}
// 或者
private static Message postProcessMessage(Message message) {
message.getMessageProperties().setDelayLong(10000L);
return message;
}
@Test
void sendTTLMessage() {
rabbitTemplate.convertAndSend("delay.direct", "delay", "delay message", PublisherApplicationTests::postProcessMessage);
}
// 上述方法调用等价于
// message -> PublisherApplicationTests.postProcessMessage(message)延迟消息弊端
基本上所有的的定时功能(redis除外)都会有一些性能损耗,因为在程序内部维护一个时钟,每隔一段时间往前跳一次, 当定时任务很多的时候每个定时任务都会维护一个自己的时钟,就需要cpu不断计算,定时任务越多,对于cpu占用越多,所以定时任务属于cpu密集型任务, 所以采用延迟消息就会给服务器的压力带来额外的压力,特别是如果有非常多的延迟消息的时候,就会给服务器带来很多的压力, 所以定时任务(延迟消息)不能将时间设置的很长,所以mq的延迟消息只适合延迟时间较短的场景
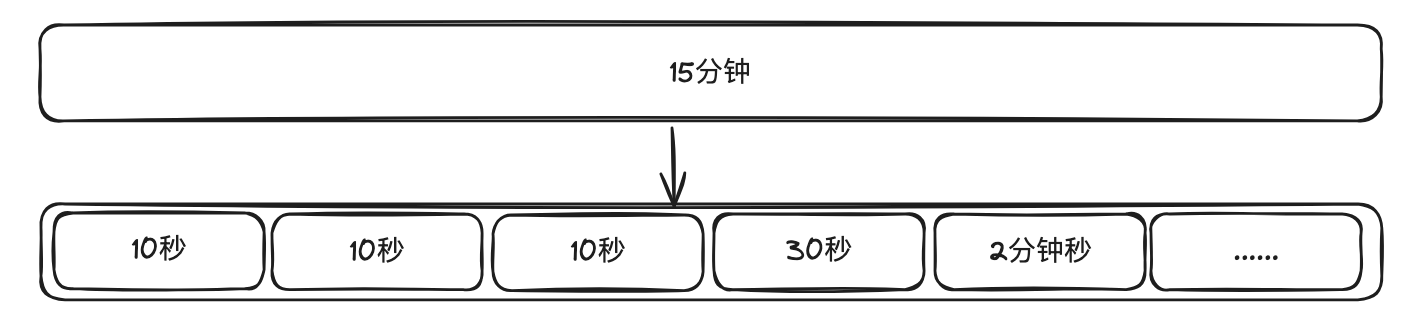
延迟消息引申
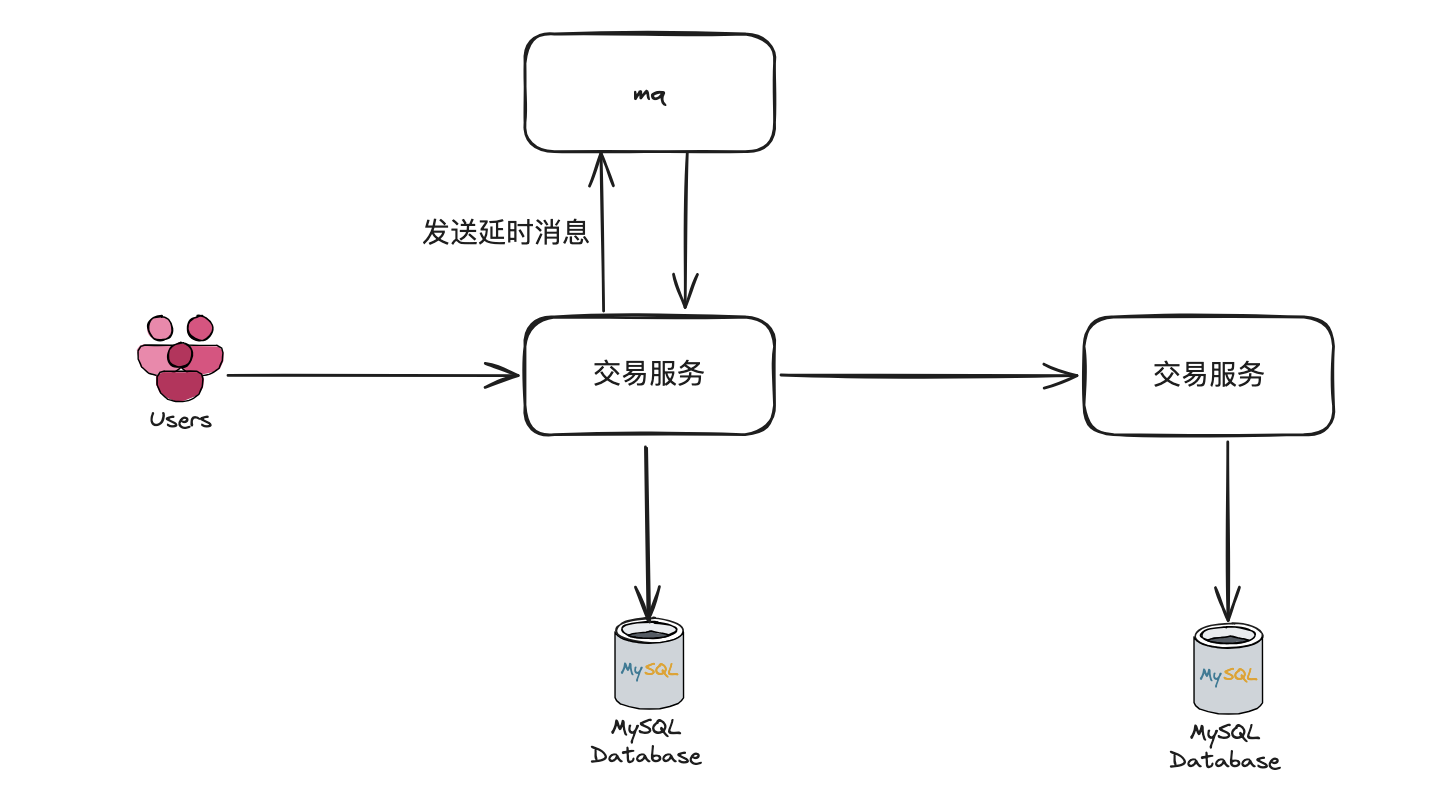
- 用户下单后,到交易服务,交易服务新增一个15分钟的延迟消息,到mq,但是后续会有一些问题,在大多数情况下,用户下完单后会马上付款, 所以如果每一个订单都发15分钟的延时消息就会浪费很多cpu
- 根据业务考虑可以将15分钟的定时任务拆成一个个小的定时任务比如10s,如果用户10s后还是没有支付,那么就再重新发布一个延时消息, 可以逐步增加这个延时消息的时常, 这样可以减轻mq的压力